数字快速记忆法训练100,深度学习入门初探-hello word式的手写数字识别一

摘要:
对于深度学习来说,手写数字识别和编程语言第一程式打印hello word应该属于一个级别的了,下面先看下手写数字识别的数据是什么,然后以此学习几个概念。1 手写数字识别数据集MNISTMNIST 数据集由
对于深度学习来说,手写数字识别和编程语言第一程式打印hello word应该属于一个级别的了,下面先看下手写数字识别的数据是什么,然后以此学习几个概念。
1 手写数字识别数据集MNIST
MNIST 数据集由 0-9 单个数字的图片构成,训练图像6万个和1万个测试样本。对于数据的组成形式,代码来得更直观一些。简单的来说就是28*28像素的灰度图,shape成一维的就是784个数据,剩下的就是批处理多少个的问题了。这里建议大家熟悉一下数据在张量里的常见表示NCHW,对图像来说,就是多少张,多少通道,高,宽。
pickle呢,这里只是将数据进行了统一的序列化放置在了一个文件下面。序列化后文件中数据会以((训练图像,训练标签),(测试图像,测试标签))的形式存入,load后亦是如此。独热码是否截图可以看到,一个就是正确解标签,另一个是只有一个1的数组。
# coding: utf-8try: import urllib.requestexcept ImportError: raise ImportError('You should use Python 3.x')import os.pathimport gzipimport pickleimport sys, osimport numpy as npfrom PIL import Image
url_base = 'http://yann.lecun.com/exdb/mnist/'key_file = { 'train_img':'train-images-idx3-ubyte.gz', 'train_label':'train-labels-idx1-ubyte.gz', 'test_img':'t10k-images-idx3-ubyte.gz', 'test_label':'t10k-labels-idx1-ubyte.gz'}
dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"train_num = 60000test_num = 10000img_dim = (1, 28, 28)
img_size = 784def _download(file_name):
file_path = dataset_dir + "/" + file_name
if os.path.exists(file_path): return
print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(url_base + file_name, file_path)
print("Done")
def download_mnist(): for v in key_file.values():
_download(v)
def _load_label(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...") with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labelsdef _load_img(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
def _convert_numpy():
dataset = {}
dataset['train_img'] = _load_img(key_file['train_img'])
dataset['train_label'] = _load_label(key_file['train_label'])
dataset['test_img'] = _load_img(key_file['test_img'])
dataset['test_label'] = _load_label(key_file['test_label'])
return datasetdef init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...") with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
print("Done!")def _change_one_hot_label(X):
T = np.zeros((X.size, 10)) for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False): """读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值规一化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
""" if not os.path.exists(save_file):
init_mnist()
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
if normalize: for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten: for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28) return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
init_mnist()
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)# 训练的第一张图 数字5img = x_train[0]
label = t_train[0]
print(label)
print(img.shape) # (784,)img = img.reshape(28, 28) # 把图像的形状变为原来的尺寸print(img.shape) # (28, 28)pil_img = Image.fromarray(np.uint8(img*255)).convert("1")
pil_img.show()#(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=True)# 训练的第一张图 数字[0,0,0,0,0,1,0,0,0,0,]#label = t_train[0]#print(label)上面的代码涉及到两个重要的概念:预处理和规一化(正规化),神经网络的输入数据在正式进入处理之前都是需要做一些规格上的统一的,这就是预处理。手段其实很多,除了这里的归一化外,还有数据白化、数据均匀化等。在图像显示的时候为什么*255?

tags:
数字编程记忆法
其他相关

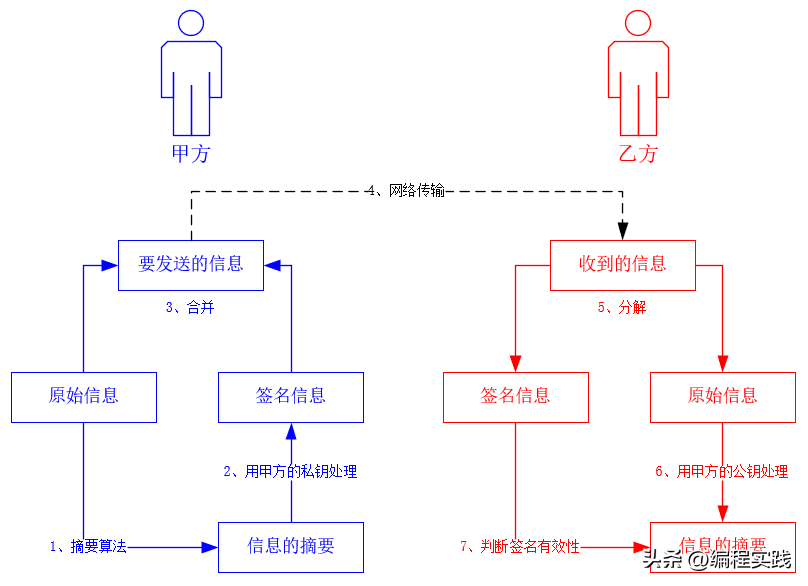
7遍记忆法,编程中常用的加密算法
作者:
极简大道
时间:2022-10-16
阅读: 154
概述编程中常见的加密算法有以下几种,它们在不同场景中分别有应用。除信息摘要算法外,其它加密方式都会需要密钥。...
全脑数字编码记忆法,和孩子们一起走进计算演变过程的大冒险吧
作者:
极简大道
时间:2022-10-16
阅读: 255
你听说过云计算吗?你听说过大数据吗?你听说过量子计算机吗?如果它们对于你来说比较陌生,那你一定知道智能手机。因为它就在我们的日常生活中。最早的手机,是一个像水壶一样的大哥大,它只能用来打电话。而我们所处的年代,随着5G时代的来临,手机就仿如一只可随身携带的缩小型手提电脑。智能手机也是钱包,可以上网、购物、处理邮件、上直播课学习等等。...
数字代表文字,深度学习入门初探-hello word式的手写数字识别二
作者:
极简大道
时间:2022-10-16
阅读: 231
对于深度学习来说,手写数字识别和编程语言第一程式打印hello word应该属于一个级别的了,下面先看下手写数字识别的网络会是什么样子,然后以此学习几个概念。MNIST 数据集见上文...
数字编码记忆法,计算机中的计数方法(上)
作者:
极简大道
时间:2022-10-16
阅读: 199
在计算机中,信息有两大类,一类为控制信息,一类为数据信息,这两类信息,都是由二进制数字表示。控制信息就是我们编程中常说的机器码。数据信息又可细分为数字信息和非数字信息。非数字信息有文字、图片、视频等,都有着自己对应的二进制编码规则。数字信息就是我们常说的数学上的数字,按照正负可分为:正数、负数,按照小数情况可分为:纯整数、纯小数、带小数整数,这些数在计算机上编码一般有四种:原码、反码、补码、移码。...
精选推荐
- [记忆方法] 最有效的备考方法,法考如何备考,2021年高考备考:8种高效记忆方法
- [记忆方法] 考前快速大量记忆技巧,最有效的备考方法,考前冲刺:一消备考也要动脑筋,这样记忆方法大多数考生并不知道
- [记忆方法] 怎样快速记忆知识点且记得牢,考前快速大量记忆技巧,会计从业备考不放假,六大归纳记忆法带你飞!
- [记忆方法] 快速记忆方法的小窍门,怎样快速记忆知识点且记得牢,这些记忆方法让你学习、备考的效率大大提升!
- [精品记忆课] 记忆课程有没有效果,记忆力课程,“超强记忆”吸引家长买了课,没上几节校长就失联,41名家长能要回16万余元的培训费用吗?
- [精品记忆课] 最强大脑记忆训练法视频,记忆课程有没有效果,超强记忆系统课_第2节 底层逻辑篇 超强记忆系统课_第2节
- [古诗词记忆] 孩子记忆力差,背书困难怎么办,有什么快速背书的方法,有用的背书方法,快收藏码住吧~
- [记忆方法] 记忆的方法和技巧,记忆宫殿训练方法,技巧:熟记这些顺口溜,轻松记忆历史朝代知识
- [记忆方法] 历史朝代记忆口诀,记忆的方法和技巧,我国历史朝代顺序记忆口诀
- [古诗词记忆] 文科怎么背怎样才能记得住,文科背书怎么背得快又牢固,文科成绩难提高?你需要这12个方法

最有效的备考方法,法考如何备考,2021年高考备考:8种高效记忆方法

考前快速大量记忆技巧,最有效的备考方法,考前冲刺:一消备考也要动脑筋,这样记忆方法大多数考生并不知道