数字代表文字,深度学习入门初探-hello word式的手写数字识别二

摘要:
对于深度学习来说,手写数字识别和编程语言第一程式打印hello word应该属于一个级别的了,下面先看下手写数字识别的网络会是什么样子,然后以此学习几个概念。MNIST 数据集见上文
对于深度学习来说,手写数字识别和编程语言第一程式打印hello word应该属于一个级别的了,下面先看下手写数字识别的网络会是什么样子,然后以此学习几个概念。
MNIST 数据集见上文深度学习入门初探——hello word式的手写数字识别一
2 手写数字识别的推理处理
推理处理呢也称为神经网络的前向传播,这里假设训练已经结束,神经网络是个现成的,存储在sample_weight.pkl这个文件中。来看看这个网络是个什么样子哈。
数据的加载上一节已经介绍过了,现在来看看sample_weight.pkl这个网络所呈现的样子:
a、输入数据是是28*28像素的灰度图,shape成一维的就是784个数据。
b、输入层的神经元和数据一致,784个神经元。产生了50个特征,这个50是可以设计的。
c、接下来的一层为了和输入层产生的输出,这个就必须是50个神经元了,产生了100个特征,也是可以设计的。
d、输出层就只能是100个神经元了,因为这一层就要输出最终结果了,只能是10了,意即0-9共10个类别。
关于激活每一层的激活函数以及最后的softmax函数可参见下面两节的实现,独热码在这里利于概率化的输出:
# coding: utf-8import sys, os
sys.path.append(os.pardir)import numpy as npimport picklefrom common.functions import sigmoid, softmaxdef _change_one_hot_label(X):
T = np.zeros((X.size, 10)) for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False): """读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
with open("mnist.pkl", 'rb') as f:
dataset = pickle.load(f)
if normalize: for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten: for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28) return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False) return x_test, t_testdef init_network(): with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f) return networkdef predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3) return y
np.set_printoptions(formatter={'float': '{: 0.9f}'.format})
x, t = get_data()
network = init_network()
print("\n\n输入数据的维度 :",x[0].shape, "\n")
print("输入层的神经元 w b :",network['W1'].shape, " ",network['b1'].shape, "\n")
print("隐藏层的神经元 w b :",network['W2'].shape, " ",network['b2'].shape, "\n")
print("输出层的神经元 w b :",network['W3'].shape, " ",network['b3'].shape, "\n")
y = predict(network, x[0])
print("预测的输出softmax概率:\n",y, "\n")
p= np.argmax(y)
print("预测的结果: ",p, "\n", "\n", "\n")3 批处理
神经网络的输入不是一个个图像了,而是多个图像,上图中输入数据的维度就是[batch_size,784],矩阵乘法的规则这个batch_size是一直传递下去的,这里注意下,结果数据在取最大值索引时的维度即可。
这个批的大小跟在计算机系统的内存和算力很大关系,同时在训练的过程中批处理也有很多好处的,这个后面遇到了再学习。
# coding: utf-8import sys, os
sys.path.append(os.pardir)
import numpy as npimport picklefrom common.functions import sigmoid, softmaxdef _change_one_hot_label(X):
T = np.zeros((X.size, 10)) for idx, row in enumerate(T):
row[X[idx]] = 1 return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False): with open("mnist.pkl", 'rb') as f:
dataset = pickle.load(f)
if normalize: for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten: for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28) return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False) return x_test, t_testdef init_network(): with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f) return networkdef predict(network, x):
w1, w2, w3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, w3) + b3
y = softmax(a3) return y
x, t = get_data()
network = init_network()
batch_size = 100 # 批数量accuracy_cnt = 0for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))

tags:
数字编程记忆法
其他相关

7遍记忆法,编程中常用的加密算法
作者:
极简大道
时间:2022-10-16
阅读: 154
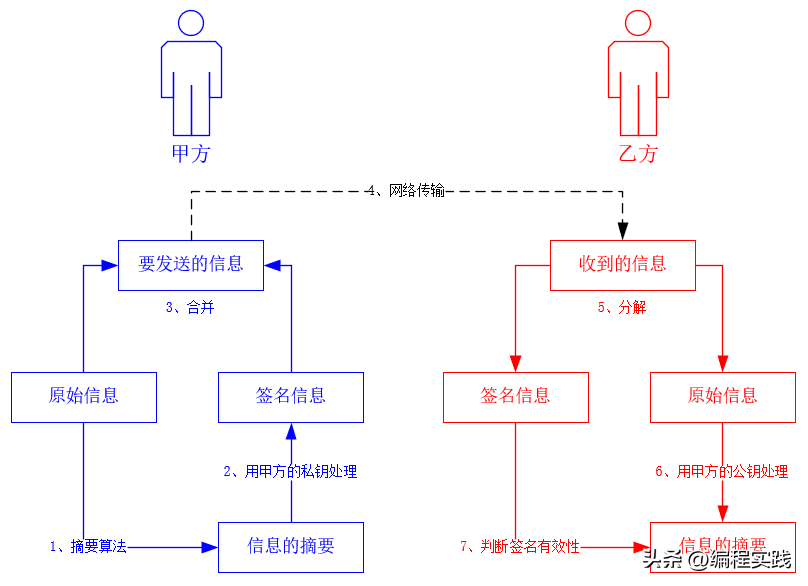
概述编程中常见的加密算法有以下几种,它们在不同场景中分别有应用。除信息摘要算法外,其它加密方式都会需要密钥。...
全脑数字编码记忆法,和孩子们一起走进计算演变过程的大冒险吧
作者:
极简大道
时间:2022-10-16
阅读: 255
你听说过云计算吗?你听说过大数据吗?你听说过量子计算机吗?如果它们对于你来说比较陌生,那你一定知道智能手机。因为它就在我们的日常生活中。最早的手机,是一个像水壶一样的大哥大,它只能用来打电话。而我们所处的年代,随着5G时代的来临,手机就仿如一只可随身携带的缩小型手提电脑。智能手机也是钱包,可以上网、购物、处理邮件、上直播课学习等等。...
数字快速记忆法训练100,深度学习入门初探-hello word式的手写数字识别一
作者:
极简大道
时间:2022-10-16
阅读: 209
对于深度学习来说,手写数字识别和编程语言第一程式打印hello word应该属于一个级别的了,下面先看下手写数字识别的数据是什么,然后以此学习几个概念。1 手写数字识别数据集MNISTMNIST 数据集由 ...
数字编码记忆法,计算机中的计数方法(上)
作者:
极简大道
时间:2022-10-16
阅读: 199
在计算机中,信息有两大类,一类为控制信息,一类为数据信息,这两类信息,都是由二进制数字表示。控制信息就是我们编程中常说的机器码。数据信息又可细分为数字信息和非数字信息。非数字信息有文字、图片、视频等,都有着自己对应的二进制编码规则。数字信息就是我们常说的数学上的数字,按照正负可分为:正数、负数,按照小数情况可分为:纯整数、纯小数、带小数整数,这些数在计算机上编码一般有四种:原码、反码、补码、移码。...
精选推荐
- [记忆方法] 最有效的备考方法,法考如何备考,2021年高考备考:8种高效记忆方法
- [记忆方法] 考前快速大量记忆技巧,最有效的备考方法,考前冲刺:一消备考也要动脑筋,这样记忆方法大多数考生并不知道
- [记忆方法] 怎样快速记忆知识点且记得牢,考前快速大量记忆技巧,会计从业备考不放假,六大归纳记忆法带你飞!
- [记忆方法] 快速记忆方法的小窍门,怎样快速记忆知识点且记得牢,这些记忆方法让你学习、备考的效率大大提升!
- [精品记忆课] 记忆课程有没有效果,记忆力课程,“超强记忆”吸引家长买了课,没上几节校长就失联,41名家长能要回16万余元的培训费用吗?
- [精品记忆课] 最强大脑记忆训练法视频,记忆课程有没有效果,超强记忆系统课_第2节 底层逻辑篇 超强记忆系统课_第2节
- [古诗词记忆] 孩子记忆力差,背书困难怎么办,有什么快速背书的方法,有用的背书方法,快收藏码住吧~
- [记忆方法] 记忆的方法和技巧,记忆宫殿训练方法,技巧:熟记这些顺口溜,轻松记忆历史朝代知识
- [记忆方法] 历史朝代记忆口诀,记忆的方法和技巧,我国历史朝代顺序记忆口诀
- [古诗词记忆] 文科怎么背怎样才能记得住,文科背书怎么背得快又牢固,文科成绩难提高?你需要这12个方法

最有效的备考方法,法考如何备考,2021年高考备考:8种高效记忆方法

考前快速大量记忆技巧,最有效的备考方法,考前冲刺:一消备考也要动脑筋,这样记忆方法大多数考生并不知道